Introduction
Recall from the previous post that the Hare growth parameter undergoes Brownian motion so that the further into the future we go, the less certain we are about it. In order to ensure that this parameter remains positive, let’s model the log of it to be Brownian motion.
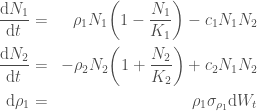
where the final equation is a stochastic differential equation with 
By Itô we have

Again, we see that the populations become noisier the further into the future we go.

Inference
Now let us infer the growth rate using Hamiltonian Monte Carlo and the domain specific probabilistic language Stan (Stan Development Team (2015b), Stan Development Team (2015a), Hoffman and Gelman (2014), Carpenter (2015)). Here’s the model expressed in Stan.
functions {
real f1 (real a, real k1, real b, real p, real z) {
real q;
q = a * p * (1 - p / k1) - b * p * z;
return q;
}
real f2 (real d, real k2, real c, real p, real z) {
real q;
q = -d * z * (1 + z / k2) + c * p * z;
return q;
}
}
data {
int<lower=1> T; // Number of observations
real y[T]; // Observed hares
real k1; // Hare carrying capacity
real b; // Hare death rate per lynx
real d; // Lynx death rate
real k2; // Lynx carrying capacity
real c; // Lynx birth rate per hare
real deltaT; // Time step
}
parameters {
real<lower=0> mu;
real<lower=0> sigma;
real<lower=0> p0;
real<lower=0> z0;
real<lower=0> rho0;
real w[T];
}
transformed parameters {
real<lower=0> p[T];
real<lower=0> z[T];
real<lower=0> rho[T];
p[1] = p0;
z[1] = z0;
rho[1] = rho0;
for (t in 1:(T-1)){
p[t+1] = p[t] + deltaT * f1 (exp(rho[t]), k1, b, p[t], z[t]);
z[t+1] = z[t] + deltaT * f2 (d, k2, c, p[t], z[t]);
rho[t+1] = rho[t] * exp(sigma * sqrt(deltaT) * w[t] - 0.5 * sigma * sigma * deltaT);
}
}
model {
mu ~ uniform(0.0,1.0);
sigma ~ uniform(0.0, 0.5);
p0 ~ lognormal(log(100.0), 0.2);
z0 ~ lognormal(log(50.0), 0.1);
rho0 ~ normal(log(mu), sigma);
w ~ normal(0.0,1.0);
for (t in 1:T) {
y[t] ~ lognormal(log(p[t]),0.1);
}
}Let’s look at the posteriors of the hyper-parameters for the Hare growth parameter.

Again, the estimate for 

Appendix: The R Driving Code
All code including the R below can be downloaded from github.
install.packages("devtools")
library(devtools)
install_github("libbi/RBi",ref="master")
install_github("sbfnk/RBi.helpers",ref="master")
rm(list = ls(all.names=TRUE))
unlink(".RData")
library('RBi')
try(detach(package:RBi, unload = TRUE), silent = TRUE)
library(RBi, quietly = TRUE)
library('RBi.helpers')
library('ggplot2', quietly = TRUE)
library('gridExtra', quietly = TRUE)
endTime <- 50
PP <- bi_model("PP.bi")
synthetic_dataset_PP <- bi_generate_dataset(endtime=endTime,
model=PP,
seed="42",
verbose=TRUE,
add_options = list(
noutputs=500))
rdata_PP <- bi_read(synthetic_dataset_PP)
df <- data.frame(rdata_PP$P$nr,
rdata_PP$P$value,
rdata_PP$Z$value,
rdata_PP$P_obs$value)
ggplot(df, aes(rdata_PP$P$nr, y = Population, color = variable), size = 0.1) +
geom_line(aes(y = rdata_PP$P$value, col = "Hare"), size = 0.1) +
geom_line(aes(y = rdata_PP$Z$value, col = "Lynx"), size = 0.1) +
geom_point(aes(y = rdata_PP$P_obs$value, col = "Observations"), size = 0.1) +
theme(legend.position="none") +
ggtitle("Example Data") +
xlab("Days") +
theme(axis.text=element_text(size=4),
axis.title=element_text(size=6,face="bold")) +
theme(plot.title = element_text(size=10))
ggsave(filename="diagrams/LVdata.png",width=4,height=3)
library(rstan)
rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())
lvStanModel <- stan_model(file = "SHO.stan",verbose=TRUE)
lvFit <- sampling(lvStanModel,
seed=42,
data=list(T = length(rdata_PP$P_obs$value),
y = rdata_PP$P_obs$value,
k1 = 2.0e2,
b = 2.0e-2,
d = 4.0e-1,
k2 = 2.0e1,
c = 4.0e-3,
deltaT = rdata_PP$P_obs$time[2] - rdata_PP$P_obs$time[1]
),
chains=1)
samples <- extract(lvFit)
gs1 <- qplot(x = samples$mu, y = ..density.., geom = "histogram") + xlab(expression(\mu))
gs2 <- qplot(x = samples$sigma, y = ..density.., geom = "histogram") + xlab(expression(samples$sigma))
gs3 <- grid.arrange(gs1, gs2)
ggsave(plot=gs3,filename="diagrams/LvPosteriorStan.png",width=4,height=3)
synthetic_dataset_PP1 <- bi_generate_dataset(endtime=endTime,
model=PP,
init = list(P = 100, Z=50),
seed="42",
verbose=TRUE,
add_options = list(
noutputs=500))
rdata_PP1 <- bi_read(synthetic_dataset_PP1)
synthetic_dataset_PP2 <- bi_generate_dataset(endtime=endTime,
model=PP,
init = list(P = 150, Z=25),
seed="42",
verbose=TRUE,
add_options = list(
noutputs=500))
rdata_PP2 <- bi_read(synthetic_dataset_PP2)
df1 <- data.frame(hare = rdata_PP$P$value,
lynx = rdata_PP$Z$value,
hare1 = rdata_PP1$P$value,
lynx1 = rdata_PP1$Z$value,
hare2 = rdata_PP2$P$value,
lynx2 = rdata_PP2$Z$value)
ggplot(df1) +
geom_path(aes(x=df1$hare, y=df1$lynx, col = "0"), size = 0.1) +
geom_path(aes(x=df1$hare1, y=df1$lynx1, col = "1"), size = 0.1) +
geom_path(aes(x=df1$hare2, y=df1$lynx2, col = "2"), size = 0.1) +
theme(legend.position="none") +
ggtitle("Phase Space") +
xlab("Hare") +
ylab("Lynx") +
theme(axis.text=element_text(size=4),
axis.title=element_text(size=6,face="bold")) +
theme(plot.title = element_text(size=10))
ggsave(filename="diagrams/PPviaLibBi.png",width=4,height=3)
PPInfer <- bi_model("PPInfer.bi")
bi_object_PP <- libbi(client="sample", model=PPInfer, obs = synthetic_dataset_PP)
bi_object_PP$run(add_options = list(
"end-time" = endTime,
noutputs = endTime,
nsamples = 2000,
nparticles = 128,
seed=42,
nthreads = 1),
verbose = TRUE,
stdoutput_file_name = tempfile(pattern="pmmhoutput", fileext=".txt"))
bi_file_summary(bi_object_PP$result$output_file_name)
mu <- bi_read(bi_object_PP, "mu")$value
g1 <- qplot(x = mu[2001:4000], y = ..density.., geom = "histogram") + xlab(expression(mu))
sigma <- bi_read(bi_object_PP, "sigma")$value
g2 <- qplot(x = sigma[2001:4000], y = ..density.., geom = "histogram") + xlab(expression(sigma))
g3 <- grid.arrange(g1, g2)
ggsave(plot=g3,filename="diagrams/LvPosterior.png",width=4,height=3)
df2 <- data.frame(hareActs = rdata_PP$P$value,
hareObs = rdata_PP$P_obs$value)
ggplot(df, aes(rdata_PP$P$nr, y = value, color = variable)) +
geom_line(aes(y = rdata_PP$P$value, col = "Phyto")) +
geom_line(aes(y = rdata_PP$Z$value, col = "Zoo")) +
geom_point(aes(y = rdata_PP$P_obs$value, col = "Phyto Obs"))
ln_alpha <- bi_read(bi_object_PP, "ln_alpha")$value
P <- matrix(bi_read(bi_object_PP, "P")$value,nrow=51,byrow=TRUE)
Z <- matrix(bi_read(bi_object_PP, "Z")$value,nrow=51,byrow=TRUE)
data50 <- bi_generate_dataset(endtime=endTime,
model=PP,
seed="42",
verbose=TRUE,
add_options = list(
noutputs=50))
rdata50 <- bi_read(data50)
df3 <- data.frame(days = c(1:51), hares = rowMeans(P), lynxes = rowMeans(Z),
actHs = rdata50$P$value, actLs = rdata50$Z$value)
ggplot(df3) +
geom_line(aes(x = days, y = hares, col = "Est Phyto")) +
geom_line(aes(x = days, y = lynxes, col = "Est Zoo")) +
geom_line(aes(x = days, y = actHs, col = "Act Phyto")) +
geom_line(aes(x = days, y = actLs, col = "Act Zoo"))Bibliography
Carpenter, Bob. 2015. “Stan: A Probabilistic Programming Language.” Journal of Statistical Software.
Hoffman, Matthew D., and Andrew Gelman. 2014. “The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo.” Journal of Machine Learning Research.
Stan Development Team. 2015a. Stan Modeling Language User’s Guide and Reference Manual, Version 2.10.0. http://mc-stan.org/.
———. 2015b. “Stan: A C++ Library for Probability and Sampling, Version 2.10.0.” http://mc-stan.org/.
