Introduction
We previously used importance sampling in the case where we did not have a sampler available for the distribution from which we wished to sample. There is an even more compelling case for using importance sampling.
Suppose we wish to estimate the probability of a rare event. For example, suppose we wish to estimate 


> module Girsanov where
> import qualified Data.Vector as V
> import Data.Random.Source.PureMT
> import Data.Random
> import Control.Monad.State
> import Data.Histogram.Fill
> import Data.Histogram.Generic ( Histogram )
> import Data.Number.Erf
> import Data.List ( transpose )
> samples :: (Foldable f, MonadRandom m) =>
> (Int -> RVar Double -> RVar (f Double)) ->
> Int ->
> m (f Double)
> samples repM n = sample $ repM n $ stdNormal
> biggerThan5 :: Int
> biggerThan5 = length (evalState xs (pureMT 42))
> where
> xs :: MonadRandom m => m [Double]
> xs = liftM (filter (>= 5.0)) $ samples replicateM 100000
As we might have expected, even if we draw 100,000 samples, we estimate this probability quite poorly.
ghci> biggerThan5
0
Using importance sampling we can do a lot better.
Let 
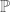
![\displaystyle \begin{aligned} \mathbb{P}_\xi((-\infty, b]) &= \frac{1}{\sqrt{2\pi}}\int_{-\infty}^b e^{-x^2/2}\,\mathrm{d}x \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cbegin%7Baligned%7D++%5Cmathbb%7BP%7D_%5Cxi%28%28-%5Cinfty%2C+b%5D%29++%26%3D+%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Cpi%7D%7D%5Cint_%7B-%5Cinfty%7D%5Eb+e%5E%7B-x%5E2%2F2%7D%5C%2C%5Cmathrm%7Bd%7Dx++%5Cend%7Baligned%7D++&bg=ffffff&fg=444444&s=0&c=20201002)
Thus
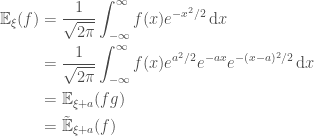
where we have defined
![\displaystyle g(x) \triangleq e^{a^2/2}e^{-a x} \quad \mathrm{and} \quad \mathbb{\tilde{P}}((-\infty, b]) \triangleq \int_{-\infty}^b g(x)\,\mathrm{d}x](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++g%28x%29+%5Ctriangleq+e%5E%7Ba%5E2%2F2%7De%5E%7B-a+x%7D++%5Cquad+%5Cmathrm%7Band%7D+%5Cquad++%5Cmathbb%7B%5Ctilde%7BP%7D%7D%28%28-%5Cinfty%2C+b%5D%29+%5Ctriangleq+%5Cint_%7B-%5Cinfty%7D%5Eb+g%28x%29%5C%2C%5Cmathrm%7Bd%7Dx++&bg=ffffff&fg=444444&s=0&c=20201002)
Thus we can estimate

Let’s try this out.
> biggerThan5' :: Double
> biggerThan5' = sum (evalState xs (pureMT 42)) / (fromIntegral n)
> where
> xs :: MonadRandom m => m [Double]
> xs = liftM (map g) $
> liftM (filter (>= 5.0)) $
> liftM (map (+5)) $
> samples replicateM n
> g x = exp $ (5^2 / 2) - 5 * x
> n = 100000
And now we get quite a good estimate.
ghci> biggerThan5'
2.85776225450217e-7
Random Paths
The probability of another rare event we might wish to estimate is that of Brownian Motion crossing a boundary. For example, what is the probability of Browian Motion crossing the line 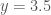
> epsilons :: (Foldable f, MonadRandom m) =>
> (Int -> RVar Double -> RVar (f Double)) ->
> Double ->
> Int ->
> m (f Double)
> epsilons repM deltaT n = sample $ repM n $ rvar (Normal 0.0 (sqrt deltaT))
> bM0to1 :: Foldable f =>
> ((Double -> Double -> Double) -> Double -> f Double -> f Double)
> -> (Int -> RVar Double -> RVar (f Double))
> -> Int
> -> Int
> -> f Double
> bM0to1 scan repM seed n =
> scan (+) 0.0 $
> evalState (epsilons repM (recip $ fromIntegral n) n) (pureMT (fromIntegral seed))
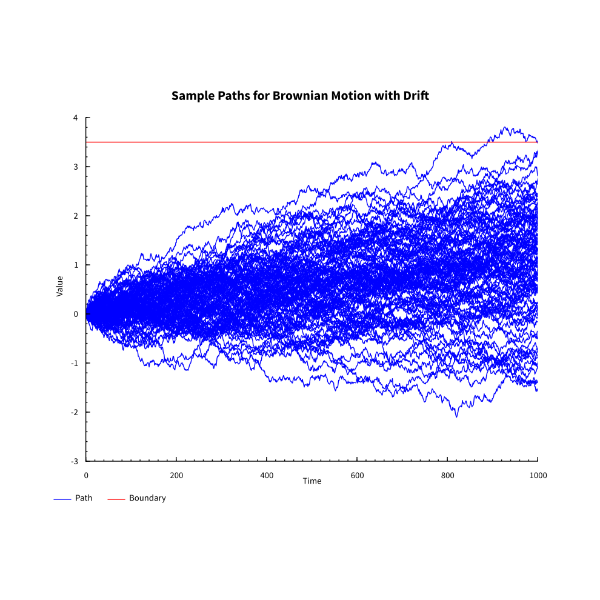
We can see by eye in the chart below that again we do quite poorly.
We know that 
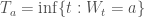
> p :: Double -> Double -> Double
> p a t = 2 * (1 - normcdf (a / sqrt t))
ghci> p 1.0 1.0
0.31731050786291415
ghci> p 2.0 1.0
4.550026389635842e-2
ghci> p 3.0 1.0
2.699796063260207e-3
But what if we didn’t know this formula? Define

where 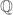
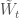
We can estimate the expectation of

where 
> n = 500
> m = 10000
> supAbove :: Double -> Double
> supAbove a = fromIntegral count / fromIntegral n
> where
> count = length $
> filter (>= a) $
> map (\seed -> maximum $ bM0to1 scanl replicateM seed m) [0..n - 1]
> bM0to1WithDrift seed mu n =
> zipWith (\m x -> x + mu * m * deltaT) [0..] $
> bM0to1 scanl replicateM seed n
> where
> deltaT = recip $ fromIntegral n
ghci> supAbove 1.0
0.326
ghci> supAbove 2.0
7.0e-2
ghci> supAbove 3.0
0.0
As expected for a rare event we get an estimate of 0.
Fortunately we can use importance sampling for paths. If we take 

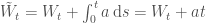
We observe that
![\displaystyle \begin{aligned} \mathbb{Q}N &= \mathbb{P}\bigg(N\frac{\mathrm{d} \mathbb{Q}}{\mathrm{d} \mathbb{P}}\bigg) \\ &= \mathbb{P}\Bigg[N \exp \Bigg(-\int_0^1 \mu(\omega,t) \,\mathrm{d}W_t - \frac{1}{2} \int_0^1 \mu^2(\omega, t) \,\mathrm{d} t\Bigg) \Bigg] \\ &= \mathbb{P}\Bigg[N \exp \Bigg(-aW_1 - \frac{1}{2} a^2\Bigg) \Bigg] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cbegin%7Baligned%7D++%5Cmathbb%7BQ%7DN+%26%3D+%5Cmathbb%7BP%7D%5Cbigg%28N%5Cfrac%7B%5Cmathrm%7Bd%7D+%5Cmathbb%7BQ%7D%7D%7B%5Cmathrm%7Bd%7D+%5Cmathbb%7BP%7D%7D%5Cbigg%29+%5C%5C++%26%3D++%5Cmathbb%7BP%7D%5CBigg%5BN++%5Cexp+%5CBigg%28-%5Cint_0%5E1++%5Cmu%28%5Comega%2Ct%29+%5C%2C%5Cmathrm%7Bd%7DW_t+-+%5Cfrac%7B1%7D%7B2%7D+%5Cint_0%5E1+%5Cmu%5E2%28%5Comega%2C+t%29+%5C%2C%5Cmathrm%7Bd%7D+t%5CBigg%29++%5CBigg%5D+%5C%5C++%26%3D++%5Cmathbb%7BP%7D%5CBigg%5BN++%5Cexp+%5CBigg%28-aW_1+-+%5Cfrac%7B1%7D%7B2%7D+a%5E2%5CBigg%29++%5CBigg%5D++%5Cend%7Baligned%7D++&bg=ffffff&fg=444444&s=0&c=20201002)
So we can also estimate the expectation of 

where 
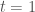
We can see from the chart below that this is going to be better at hitting the required barrier.
Let’s do some calculations.
> supAbove' a = (sum $ zipWith (*) ns ws) / fromIntegral n
> where
> deltaT = recip $ fromIntegral m
>
> uss = map (\seed -> bM0to1 scanl replicateM seed m) [0..n - 1]
> ys = map last uss
> ws = map (\x -> exp (-a * x - 0.5 * a^2)) ys
>
> vss = map (zipWith (\m x -> x + a * m * deltaT) [0..]) uss
> sups = map maximum vss
> ns = map fromIntegral $ map fromEnum $ map (>=a) sups
ghci> supAbove' 1.0
0.31592655955519156
ghci> supAbove' 2.0
4.999395029856741e-2
ghci> supAbove' 3.0
2.3859203473651654e-3
The reader is invited to try the above estimates with 1,000 samples per path to see that even with this respectable number, the calculation goes awry.
In General
If we have a probability space 
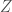



For any two probability measures when such a

Given that we managed to shift a Normal Distribution with non-zero mean in one measure to a Normal Distribution with another mean in another measure by producing the Radon-Nikodym derivative, might it be possible to shift, Brownian Motion with a drift under a one probability measure to be pure Brownian Motion under another probability measure by producing the Radon-Nikodym derivative? The answer is yes as Girsanov’s theorem below shows.
Girsanov’s Theorem
Let 
![\{{\mathcal{F}}_t\}_{t \in [0,T]}](https://s0.wp.com/latex.php?latex=%5C%7B%7B%5Cmathcal%7BF%7D%7D_t%5C%7D_%7Bt+%5Cin+%5B0%2CT%5D%7D&bg=ffffff&fg=444444&s=0&c=20201002)

![\displaystyle \mathbb{E}\bigg[\exp{\bigg(\frac{1}{2}\int_0^T \mu^2(s, \omega) \,\mathrm{d}s\bigg)}\bigg] = K < \infty](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cmathbb%7BE%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5ET+%5Cmu%5E2%28s%2C+%5Comega%29+%5C%2C%5Cmathrm%7Bd%7Ds%5Cbigg%29%7D%5Cbigg%5D+%3D+K+%3C+%5Cinfty++&bg=ffffff&fg=444444&s=0&c=20201002)
then there exists a probability measure
-
.
-
.
-
is Brownian Motion on the probabiity space
also with the filtration
.
In order to prove Girsanov’s Theorem, we need a condition which allows to infer that 
Proof
Define

Then, temporarily overloading the notation and writing 
![\displaystyle \begin{aligned} \mathbb{Q}\bigg[\exp{\int_0^T f(s) \,\mathrm{d}X_s}\bigg] &= \mathbb{Q}\bigg[\exp{\int_0^T f(s) \,\mathrm{d}W_s + \int_0^T \mu(\omega, s) \,\mathrm{d}s}\bigg] \\ &= \mathbb{P}\bigg[\exp{\bigg( \int_0^T \big(f(s) - \mu(\omega, s)\big)\,\mathrm{d}W_s + \int_0^T f(s)\mu(\omega, s)\,\mathrm{d}s - \frac{1}{2}\int_0^T \mu^2(\omega ,s) \,\mathrm{d}s \bigg)}\bigg] \\ &= \mathbb{P}\bigg[\exp{\bigg( \int_0^T \big(f(s) - \mu(\omega, s)\big)\,\mathrm{d}W_s - \frac{1}{2}\int_0^T \big(f(s) - \mu(\omega ,s)\big)^2 \,\mathrm{d}s + \frac{1}{2}\int_0^T f^2(s) \,\mathrm{d}s \bigg)}\bigg] \\ &= \frac{1}{2}\int_0^T f^2(s) \,\mathrm{d}s \, \mathbb{P}\bigg[\exp{\bigg( \int_0^T \big(f(s) - \mu(\omega, s)\big)\,\mathrm{d}W_s - \frac{1}{2}\int_0^T \big(f(s) - \mu(\omega ,s)\big)^2 \,\mathrm{d}s \bigg)}\bigg] \\ &= \frac{1}{2}\int_0^T f^2(s) \,\mathrm{d}s \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cbegin%7Baligned%7D++%5Cmathbb%7BQ%7D%5Cbigg%5B%5Cexp%7B%5Cint_0%5ET+f%28s%29+%5C%2C%5Cmathrm%7Bd%7DX_s%7D%5Cbigg%5D+%26%3D++%5Cmathbb%7BQ%7D%5Cbigg%5B%5Cexp%7B%5Cint_0%5ET+f%28s%29+%5C%2C%5Cmathrm%7Bd%7DW_s+%2B+%5Cint_0%5ET+%5Cmu%28%5Comega%2C+s%29+%5C%2C%5Cmathrm%7Bd%7Ds%7D%5Cbigg%5D+%5C%5C++%26%3D++%5Cmathbb%7BP%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28++%5Cint_0%5ET+%5Cbig%28f%28s%29+-+%5Cmu%28%5Comega%2C+s%29%5Cbig%29%5C%2C%5Cmathrm%7Bd%7DW_s+%2B++%5Cint_0%5ET+f%28s%29%5Cmu%28%5Comega%2C+s%29%5C%2C%5Cmathrm%7Bd%7Ds+-++%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5ET+%5Cmu%5E2%28%5Comega+%2Cs%29+%5C%2C%5Cmathrm%7Bd%7Ds++%5Cbigg%29%7D%5Cbigg%5D+%5C%5C++%26%3D++%5Cmathbb%7BP%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28++%5Cint_0%5ET+%5Cbig%28f%28s%29+-+%5Cmu%28%5Comega%2C+s%29%5Cbig%29%5C%2C%5Cmathrm%7Bd%7DW_s+-++%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5ET+%5Cbig%28f%28s%29+-+%5Cmu%28%5Comega+%2Cs%29%5Cbig%29%5E2+%5C%2C%5Cmathrm%7Bd%7Ds+%2B++%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5ET+f%5E2%28s%29+%5C%2C%5Cmathrm%7Bd%7Ds++%5Cbigg%29%7D%5Cbigg%5D+%5C%5C++%26%3D++%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5ET+f%5E2%28s%29+%5C%2C%5Cmathrm%7Bd%7Ds++%5C%2C++%5Cmathbb%7BP%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28++%5Cint_0%5ET+%5Cbig%28f%28s%29+-+%5Cmu%28%5Comega%2C+s%29%5Cbig%29%5C%2C%5Cmathrm%7Bd%7DW_s+-++%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5ET+%5Cbig%28f%28s%29+-+%5Cmu%28%5Comega+%2Cs%29%5Cbig%29%5E2+%5C%2C%5Cmathrm%7Bd%7Ds++%5Cbigg%29%7D%5Cbigg%5D+%5C%5C++%26%3D++%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5ET+f%5E2%28s%29+%5C%2C%5Cmathrm%7Bd%7Ds++%5Cend%7Baligned%7D++&bg=ffffff&fg=444444&s=0&c=20201002)
From whence we see that

And since this characterizes Brownian Motion, we are done.

The Novikov Sufficiency Condition
The Novikov Sufficiency Condition Statement
Let ![\mu \in {\cal{L}}^2_{\mathrm{LOC}}[0,T]](https://s0.wp.com/latex.php?latex=%5Cmu+%5Cin+%7B%5Ccal%7BL%7D%7D%5E2_%7B%5Cmathrm%7BLOC%7D%7D%5B0%2CT%5D&bg=ffffff&fg=444444&s=0&c=20201002)
then the process defined by

is a strict martingale.
Before we prove this, we need two lemmas.
Lemma 1
Let 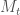
![t \in [0,t]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2Ct%5D&bg=ffffff&fg=444444&s=0&c=20201002)

Proof
Let 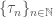


Thus

By assumption we have 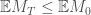
Lemma 2
Let 
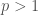
Proof
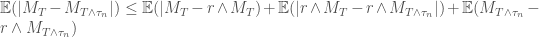
By the super-martingale property 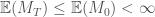

We also have that

By Chebyshev’s inequality (see note (2) below), we have

Taking limits first over 


For 


Again taking limits over

These two conclusions imply

We can therefore conclude (since 
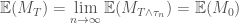
Thus by the preceeding lemma
The Novikov Sufficiency Condition Proof
Step 1
First we note that 
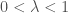
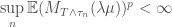
using the preceeding lemma where
We note that
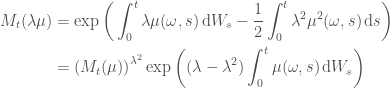
Now apply Hölder’s inequality with conjugates 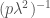
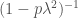

![\displaystyle \begin{aligned} \mathbb{E}((M_t(\lambda\mu))^p) &= \mathbb{E}\bigg[{(M_t(\mu))}^{p\lambda^2}\exp{\bigg(p(\lambda - \lambda^2)\int^t_0 \mu(\omega, s)\,\mathrm{d}W_s\bigg)}\bigg] \\ &\le \bigg|\bigg|{M_t(\mu)}^{p\lambda^2}\bigg|\bigg|_{p\lambda^2} \bigg|\bigg|\exp{\bigg(p(\lambda - \lambda^2)\int^t_0 \mu(\omega, s)\,\mathrm{d}W_s\bigg)}\bigg|\bigg|_{1 - p\lambda^2} \\ &= \mathbb{E}{\bigg[M_t(\mu)}\bigg]^{p\lambda^2} \mathbb{E}\bigg[\exp{\bigg(p\frac{\lambda - \lambda^2}{1 - p\lambda^2}\int^t_0 \mu(\omega, s)\,\mathrm{d}W_s\bigg)}\bigg]^{1 - p\lambda^2} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cbegin%7Baligned%7D++%5Cmathbb%7BE%7D%28%28M_t%28%5Clambda%5Cmu%29%29%5Ep%29++%26%3D++%5Cmathbb%7BE%7D%5Cbigg%5B%7B%28M_t%28%5Cmu%29%29%7D%5E%7Bp%5Clambda%5E2%7D%5Cexp%7B%5Cbigg%28p%28%5Clambda+-+%5Clambda%5E2%29%5Cint%5Et_0+%5Cmu%28%5Comega%2C+s%29%5C%2C%5Cmathrm%7Bd%7DW_s%5Cbigg%29%7D%5Cbigg%5D+%5C%5C++%26%5Cle++%5Cbigg%7C%5Cbigg%7C%7BM_t%28%5Cmu%29%7D%5E%7Bp%5Clambda%5E2%7D%5Cbigg%7C%5Cbigg%7C_%7Bp%5Clambda%5E2%7D++%5Cbigg%7C%5Cbigg%7C%5Cexp%7B%5Cbigg%28p%28%5Clambda+-+%5Clambda%5E2%29%5Cint%5Et_0+%5Cmu%28%5Comega%2C+s%29%5C%2C%5Cmathrm%7Bd%7DW_s%5Cbigg%29%7D%5Cbigg%7C%5Cbigg%7C_%7B1+-+p%5Clambda%5E2%7D+%5C%5C++%26%3D++%5Cmathbb%7BE%7D%7B%5Cbigg%5BM_t%28%5Cmu%29%7D%5Cbigg%5D%5E%7Bp%5Clambda%5E2%7D++%5Cmathbb%7BE%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28p%5Cfrac%7B%5Clambda+-+%5Clambda%5E2%7D%7B1+-+p%5Clambda%5E2%7D%5Cint%5Et_0+%5Cmu%28%5Comega%2C+s%29%5C%2C%5Cmathrm%7Bd%7DW_s%5Cbigg%29%7D%5Cbigg%5D%5E%7B1+-+p%5Clambda%5E2%7D++%5Cend%7Baligned%7D++&bg=ffffff&fg=444444&s=0&c=20201002)
Now let us choose
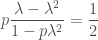
then

In order to apply Hölder’s inequality we need to check that 

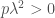



Re-writing the above inequality with this value of
![\displaystyle \begin{aligned} \mathbb{E}((M_t(\lambda\mu))^p) &\le \mathbb{E}{\bigg[M_t(\mu)}\bigg]^{p\lambda^2} \mathbb{E}\bigg[\exp{\bigg(\frac{1}{2}\int^t_0 \mu(\omega, s)\,\mathrm{d}W_s\bigg)}\bigg]^{1 - p\lambda^2} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cbegin%7Baligned%7D++%5Cmathbb%7BE%7D%28%28M_t%28%5Clambda%5Cmu%29%29%5Ep%29++%26%5Cle++%5Cmathbb%7BE%7D%7B%5Cbigg%5BM_t%28%5Cmu%29%7D%5Cbigg%5D%5E%7Bp%5Clambda%5E2%7D++%5Cmathbb%7BE%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28%5Cfrac%7B1%7D%7B2%7D%5Cint%5Et_0+%5Cmu%28%5Comega%2C+s%29%5C%2C%5Cmathrm%7Bd%7DW_s%5Cbigg%29%7D%5Cbigg%5D%5E%7B1+-+p%5Clambda%5E2%7D++%5Cend%7Baligned%7D++&bg=ffffff&fg=444444&s=0&c=20201002)
By the first lemma, since 
![\displaystyle \mathbb{E}{\bigg[M_t(\mu)}\bigg]^{p\lambda^2} \leq 1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cmathbb%7BE%7D%7B%5Cbigg%5BM_t%28%5Cmu%29%7D%5Cbigg%5D%5E%7Bp%5Clambda%5E2%7D+%5Cleq+1++&bg=ffffff&fg=444444&s=0&c=20201002)
and therefore
![\displaystyle \begin{aligned} \mathbb{E}((M_t(\lambda\mu))^p) &\le \mathbb{E}\bigg[\exp{\bigg(\frac{1}{2}\int^t_0 \mu(\omega, s)\,\mathrm{d}W_s\bigg)}\bigg]^{1 - p\lambda^2} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cbegin%7Baligned%7D++%5Cmathbb%7BE%7D%28%28M_t%28%5Clambda%5Cmu%29%29%5Ep%29++%26%5Cle++%5Cmathbb%7BE%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28%5Cfrac%7B1%7D%7B2%7D%5Cint%5Et_0+%5Cmu%28%5Comega%2C+s%29%5C%2C%5Cmathrm%7Bd%7DW_s%5Cbigg%29%7D%5Cbigg%5D%5E%7B1+-+p%5Clambda%5E2%7D++%5Cend%7Baligned%7D++&bg=ffffff&fg=444444&s=0&c=20201002)
Step 2
Recall we have

Taking logs gives
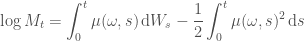
or in diferential form
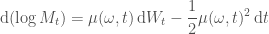
We can also apply Itô’s rule to
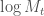
![\displaystyle \begin{aligned} \mathrm{d}(\log{M_t}) &= \frac{1}{M_t}\,\mathrm{d}M_t - \frac{1}{2}\frac{1}{M_t^2}\,\mathrm{d}[M]_t \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cbegin%7Baligned%7D++%5Cmathrm%7Bd%7D%28%5Clog%7BM_t%7D%29++%26%3D+%5Cfrac%7B1%7D%7BM_t%7D%5C%2C%5Cmathrm%7Bd%7DM_t+++-+%5Cfrac%7B1%7D%7B2%7D%5Cfrac%7B1%7D%7BM_t%5E2%7D%5C%2C%5Cmathrm%7Bd%7D%5BM%5D_t+%5C%5C++%5Cend%7Baligned%7D++&bg=ffffff&fg=444444&s=0&c=20201002)
where ![[\ldots]](https://s0.wp.com/latex.php?latex=%5B%5Cldots%5D&bg=ffffff&fg=444444&s=0&c=20201002)
Comparing terms gives the stochastic differential equation

In integral form this can also be written as
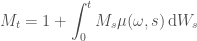
Thus 
Next we note that
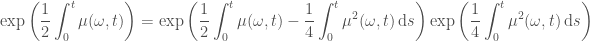
to which we can apply Hölder’s inequality with conjugates 
![\displaystyle \begin{aligned} \mathbb{E}\bigg[\exp{\bigg(\frac{1}{2}\int_0^t \mu(\omega, t)\bigg)}\bigg] &= \mathbb{E}\bigg[\exp{\bigg(\frac{1}{2}\int_0^t \mu(\omega, t) - \frac{1}{4}\int_0^t \mu^2(\omega, t) \,\mathrm{d}s \bigg)} \exp{\bigg(\frac{1}{4}\int_0^t \mu^2(\omega, t) \,\mathrm{d}s \bigg)}\bigg] \\ & \leq \sqrt{\mathbb{E}\bigg[\exp{\bigg(\int_0^t \mu(\omega, t) - \frac{1}{2}\int_0^t \mu^2(\omega, t) \,\mathrm{d}s \bigg)}\bigg]} \sqrt{\mathbb{E}\exp{\bigg(\frac{1}{2}\int_0^t \mu^2(\omega, t) \,\mathrm{d}s \bigg)}\bigg]} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cbegin%7Baligned%7D++%5Cmathbb%7BE%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5Et+%5Cmu%28%5Comega%2C+t%29%5Cbigg%29%7D%5Cbigg%5D+%26%3D++%5Cmathbb%7BE%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5Et+%5Cmu%28%5Comega%2C+t%29+-+++++++++++++++++++++++++++++%5Cfrac%7B1%7D%7B4%7D%5Cint_0%5Et+%5Cmu%5E2%28%5Comega%2C+t%29+%5C%2C%5Cmathrm%7Bd%7Ds+++++++++++++++++++++++%5Cbigg%29%7D++++++++++++++++++%5Cexp%7B%5Cbigg%28%5Cfrac%7B1%7D%7B4%7D%5Cint_0%5Et+%5Cmu%5E2%28%5Comega%2C+t%29+%5C%2C%5Cmathrm%7Bd%7Ds+++++++++++++++++++++++%5Cbigg%29%7D%5Cbigg%5D+%5C%5C++%26+%5Cleq++%5Csqrt%7B%5Cmathbb%7BE%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28%5Cint_0%5Et+%5Cmu%28%5Comega%2C+t%29+-+++++++++++++++++++++++++++++%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5Et+%5Cmu%5E2%28%5Comega%2C+t%29+%5C%2C%5Cmathrm%7Bd%7Ds+++++++++++++++++++++++%5Cbigg%29%7D%5Cbigg%5D%7D++%5Csqrt%7B%5Cmathbb%7BE%7D%5Cexp%7B%5Cbigg%28%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5Et+%5Cmu%5E2%28%5Comega%2C+t%29+%5C%2C%5Cmathrm%7Bd%7Ds+++++++++++++++++++++++%5Cbigg%29%7D%5Cbigg%5D%7D++%5Cend%7Baligned%7D++&bg=ffffff&fg=444444&s=0&c=20201002)
Applying the supermartingale inequality then gives
![\displaystyle \begin{aligned} \mathbb{E}\bigg[\exp{\bigg(\frac{1}{2}\int_0^t \mu(\omega, t)\bigg)}\bigg] & \leq \sqrt{\mathbb{E}\exp{\bigg(\frac{1}{2}\int_0^t \mu^2(\omega, t) \,\mathrm{d}s \bigg)}\bigg]} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cbegin%7Baligned%7D++%5Cmathbb%7BE%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5Et+%5Cmu%28%5Comega%2C+t%29%5Cbigg%29%7D%5Cbigg%5D++%26+%5Cleq++%5Csqrt%7B%5Cmathbb%7BE%7D%5Cexp%7B%5Cbigg%28%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5Et+%5Cmu%5E2%28%5Comega%2C+t%29+%5C%2C%5Cmathrm%7Bd%7Ds+++++++++++++++++++++++%5Cbigg%29%7D%5Cbigg%5D%7D++%5Cend%7Baligned%7D++&bg=ffffff&fg=444444&s=0&c=20201002)
Step 3
Now we can apply the result in Step 2 to the result in Step 1.
![\displaystyle \begin{aligned} \mathbb{E}((M_t(\lambda\mu))^p) &\le \mathbb{E}\bigg[\exp{\bigg(\frac{1}{2}\int^t_0 \mu(\omega, s)\,\mathrm{d}W_s\bigg)}\bigg]^{1 - p\lambda^2} \\ &\le {\mathbb{E}\bigg[\exp{\bigg(\frac{1}{2}\int_0^t \mu^2(\omega, t) \,\mathrm{d}s \bigg)}\bigg]}^{(1 - p\lambda^2)/2} \\ &\le K^{(1 - p\lambda^2)/2} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cbegin%7Baligned%7D++%5Cmathbb%7BE%7D%28%28M_t%28%5Clambda%5Cmu%29%29%5Ep%29++%26%5Cle++%5Cmathbb%7BE%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28%5Cfrac%7B1%7D%7B2%7D%5Cint%5Et_0+%5Cmu%28%5Comega%2C+s%29%5C%2C%5Cmathrm%7Bd%7DW_s%5Cbigg%29%7D%5Cbigg%5D%5E%7B1+-+p%5Clambda%5E2%7D+%5C%5C++%26%5Cle++%7B%5Cmathbb%7BE%7D%5Cbigg%5B%5Cexp%7B%5Cbigg%28%5Cfrac%7B1%7D%7B2%7D%5Cint_0%5Et+%5Cmu%5E2%28%5Comega%2C+t%29+%5C%2C%5Cmathrm%7Bd%7Ds++++++++++++++++++++++++%5Cbigg%29%7D%5Cbigg%5D%7D%5E%7B%281+-+p%5Clambda%5E2%29%2F2%7D+%5C%5C++%26%5Cle++K%5E%7B%281+-+p%5Clambda%5E2%29%2F2%7D++%5Cend%7Baligned%7D++&bg=ffffff&fg=444444&s=0&c=20201002)
We can replace 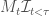

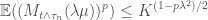
From which we can conclude
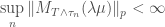
Now we can apply the second lemma to conclude that 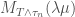
Final Step
We have already calculated that
Now apply Hölder’s inequality with conjugates 

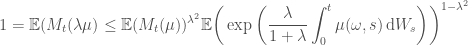
And then we can apply Jensen’s inequality to the last term on the right hand side with the convex function 

Using the inequality we established in Step 2 and the Novikov condition then gives

If we now let 
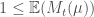
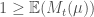
Notes
-
We have already used importance sampling and also touched on changes of measure.
-
Chebyshev’s inequality is usually stated for the second moment but the proof is easily adapted:

- We follow Handel (2007); a similar approach is given in Steele (2001).
Bibliography
Handel, Ramon von. 2007. “Stochastic Calculus, Filtering, and Stochastic Control (Lecture Notes).”
Steele, J.M. 2001. Stochastic Calculus and Financial Applications. Applications of Mathematics. Springer New York. https://books.google.co.uk/books?id=fsgkBAAAQBAJ.
