Importance Sampling
Suppose we have an random variable 
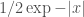
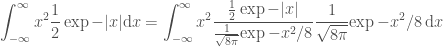
So we can sample from 
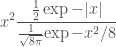
> {-# OPTIONS_GHC -Wall #-}
> {-# OPTIONS_GHC -fno-warn-name-shadowing #-}
> {-# OPTIONS_GHC -fno-warn-type-defaults #-}
> {-# OPTIONS_GHC -fno-warn-unused-do-bind #-}
> {-# OPTIONS_GHC -fno-warn-missing-methods #-}
> {-# OPTIONS_GHC -fno-warn-orphans #-}
> module Importance where
> import Control.Monad
> import Data.Random.Source.PureMT
> import Data.Random
> import Data.Random.Distribution.Binomial
> import Data.Random.Distribution.Beta
> import Control.Monad.State
> import qualified Control.Monad.Writer as W
> sampleImportance :: RVarT (W.Writer [Double]) ()
> sampleImportance = do
> x <- rvarT $ Normal 0.0 2.0
> let x2 = x^2
> u = x2 * 0.5 * exp (-(abs x))
> v = (exp ((-x2)/8)) * (recip (sqrt (8*pi)))
> w = u / v
> lift $ W.tell [w]
> return ()
> runImportance :: Int -> [Double]
> runImportance n =
> snd $
> W.runWriter $
> evalStateT (sample (replicateM n sampleImportance))
> (pureMT 2)
We can run this 10,000 times to get an estimate.
ghci> import Formatting
ghci> format (fixed 2) (sum (runImportance 10000) / 10000)
"2.03"
Since we know that the 

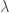
The value of

is called the weight, 

Importance Sampling Approximation of the Posterior
Suppose that the posterior distribution of a model in which we are interested has a complicated functional form and that we therefore wish to approximate it in some way. First assume that we wish to calculate the expectation of some arbitrary function 

Using Bayes
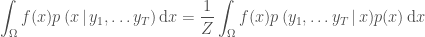
where 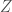
As before we can re-write this using a proposal distribution
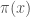

We can now sample 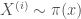

where the weights 
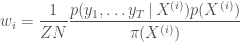
We follow Alex Cook and use the example from (Rerks-Ngarm et al. 2009). We take the prior as 

Note that we use the log of the pdf in our calculations otherwise we suffer from (silent) underflow, e.g.,
ghci> pdf (Binomial nv (0.4 :: Double)) xv
0.0
On the other hand if we use the log pdf form
ghci> logPdf (Binomial nv (0.4 :: Double)) xv
-3900.8941170876574
> xv, nv :: Int
> xv = 51
> nv = 8197
> sampleUniform :: RVarT (W.Writer [Double]) ()
> sampleUniform = do
> x <- rvarT StdUniform
> lift $ W.tell [x]
> return ()
> runSampler :: RVarT (W.Writer [Double]) () ->
> Int -> Int -> [Double]
> runSampler sampler seed n =
> snd $
> W.runWriter $
> evalStateT (sample (replicateM n sampler))
> (pureMT (fromIntegral seed))
> sampleSize :: Int
> sampleSize = 1000
> pv :: [Double]
> pv = runSampler sampleUniform 2 sampleSize
> logWeightsRaw :: [Double]
> logWeightsRaw = map (\p -> logPdf (Beta 1.0 1.0) p +
> logPdf (Binomial nv p) xv -
> logPdf StdUniform p) pv
> logWeightsMax :: Double
> logWeightsMax = maximum logWeightsRaw
>
> weightsRaw :: [Double]
> weightsRaw = map (\w -> exp (w - logWeightsMax)) logWeightsRaw
> weightsSum :: Double
> weightsSum = sum weightsRaw
> weights :: [Double]
> weights = map (/ weightsSum) weightsRaw
> meanPv :: Double
> meanPv = sum $ zipWith (*) pv weights
>
> meanPv2 :: Double
> meanPv2 = sum $ zipWith (\p w -> p * p * w) pv weights
>
> varPv :: Double
> varPv = meanPv2 - meanPv * meanPv
We get the answer
ghci> meanPv
6.400869727227364e-3
But if we look at the size of the weights and the effective sample size
ghci> length $ filter (>= 1e-6) weights
9
ghci> (sum weights)^2 / (sum $ map (^2) weights)
4.581078458313967
so we may not be getting a very good estimate. Let’s try
> sampleNormal :: RVarT (W.Writer [Double]) ()
> sampleNormal = do
> x <- rvarT $ Normal meanPv (sqrt varPv)
> lift $ W.tell [x]
> return ()
> pvC :: [Double]
> pvC = runSampler sampleNormal 3 sampleSize
> logWeightsRawC :: [Double]
> logWeightsRawC = map (\p -> logPdf (Beta 1.0 1.0) p +
> logPdf (Binomial nv p) xv -
> logPdf (Normal meanPv (sqrt varPv)) p) pvC
> logWeightsMaxC :: Double
> logWeightsMaxC = maximum logWeightsRawC
>
> weightsRawC :: [Double]
> weightsRawC = map (\w -> exp (w - logWeightsMaxC)) logWeightsRawC
> weightsSumC :: Double
> weightsSumC = sum weightsRawC
> weightsC :: [Double]
> weightsC = map (/ weightsSumC) weightsRawC
> meanPvC :: Double
> meanPvC = sum $ zipWith (*) pvC weightsC
> meanPvC2 :: Double
> meanPvC2 = sum $ zipWith (\p w -> p * p * w) pvC weightsC
>
> varPvC :: Double
> varPvC = meanPvC2 - meanPvC * meanPvC
Now the weights and the effective size are more re-assuring
ghci> length $ filter (>= 1e-6) weightsC
1000
ghci> (sum weightsC)^2 / (sum $ map (^2) weightsC)
967.113872888872
And we can take more confidence in the estimate
ghci> meanPvC
6.371225269833208e-3
Bibliography
Rerks-Ngarm, Supachai, Punnee Pitisuttithum, Sorachai Nitayaphan, Jaranit Kaewkungwal, Joseph Chiu, Robert Paris, Nakorn Premsri, et al. 2009. “Vaccination with ALVAC and AIDSVAX to Prevent HIV-1 Infection in Thailand.” New England Journal of Medicine 361 (23) (December 3): 2209–2220. doi:10.1056/nejmoa0908492. http://dx.doi.org/10.1056/nejmoa0908492.

Pingback: Girsanov’s Theorem | Maths, Stats & Functional Programming